
Public-safe workflow
01
↓
02
↓
03
↓
04
↓
05
↓
06
↓
07
Simple Version
The pipeline is the repeatable path that turns protected corpus material into public-safe aggregate evidence.
Stages
1. Prepare source text inside the private boundary
2. Generate RMR and TQT transforms
3. Run tokenizer passes
4. Generate slice windows
5. Measure metric families
6. Compile summary workbooks
7. Generate chart assets
8. Package public-safe outputs
What Each Stage Protects
The pipeline keeps source material and public material separated. Raw writing and private mappings stay inside the controlled review environment. Public outputs describe aggregate behavior, metric structure, and chart evidence.
Transform and tokenizer stages let the same underlying material be measured through multiple processing lenses. Slice windows make the result harder to explain as one favorable excerpt. Summary workbooks and chart exports create a reviewable trail from measurement to public presentation.
What This Page Proves / Does Not Prove
This page supports a process claim: PRM results are produced through a repeatable path from protected input to public-safe aggregate output.
It does not prove every source-level detail by itself, publish the protected corpus, or expose implementation-sensitive review material. The public pipeline page explains the measurement path; controlled review is where source manifests, provenance records, and reproducibility notes can be inspected under appropriate terms.
Why Repeatability Matters
The pipeline is not only about producing charts. It is about making claims auditable.
If the same corpus structure can move through the same stages and produce the same public-safe outputs, the site can separate presentation from evidence. Findings tell the story. The pipeline explains how that story was measured.

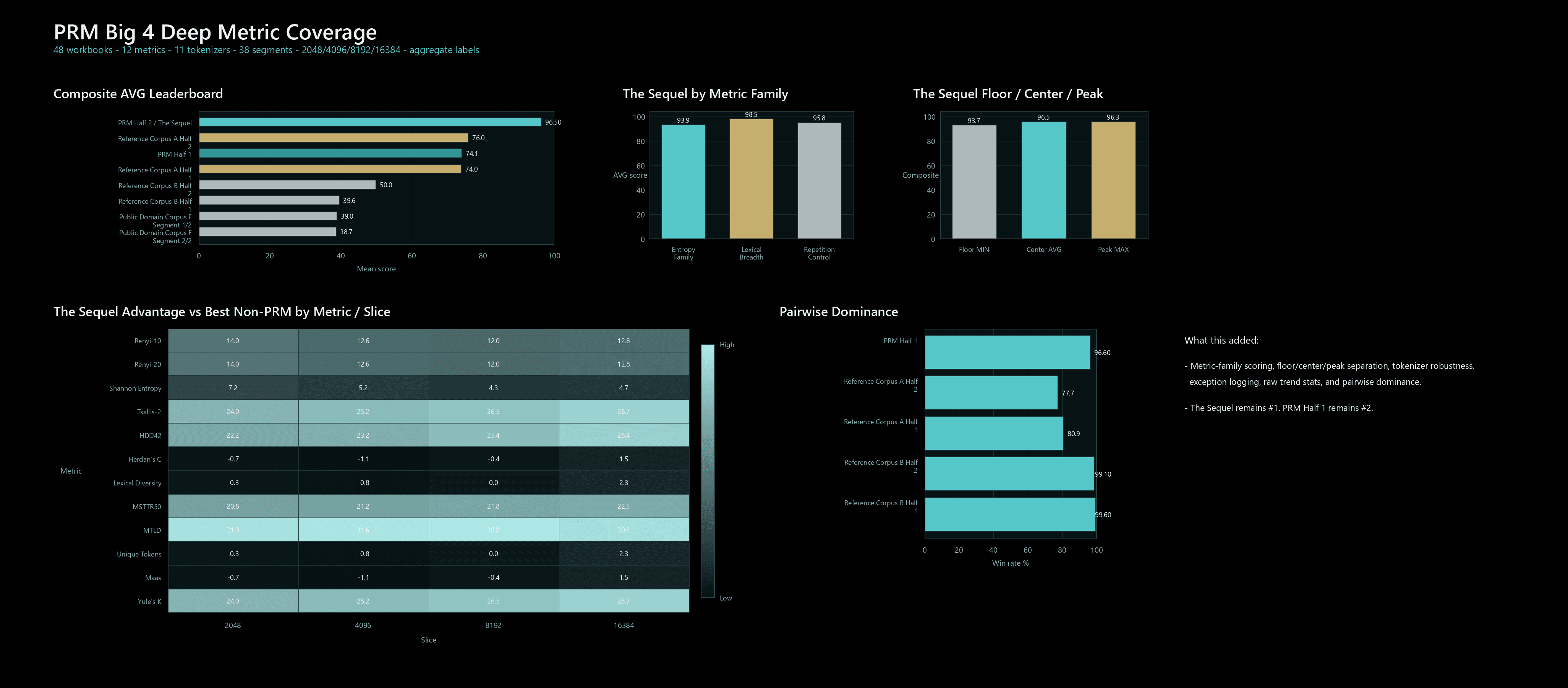
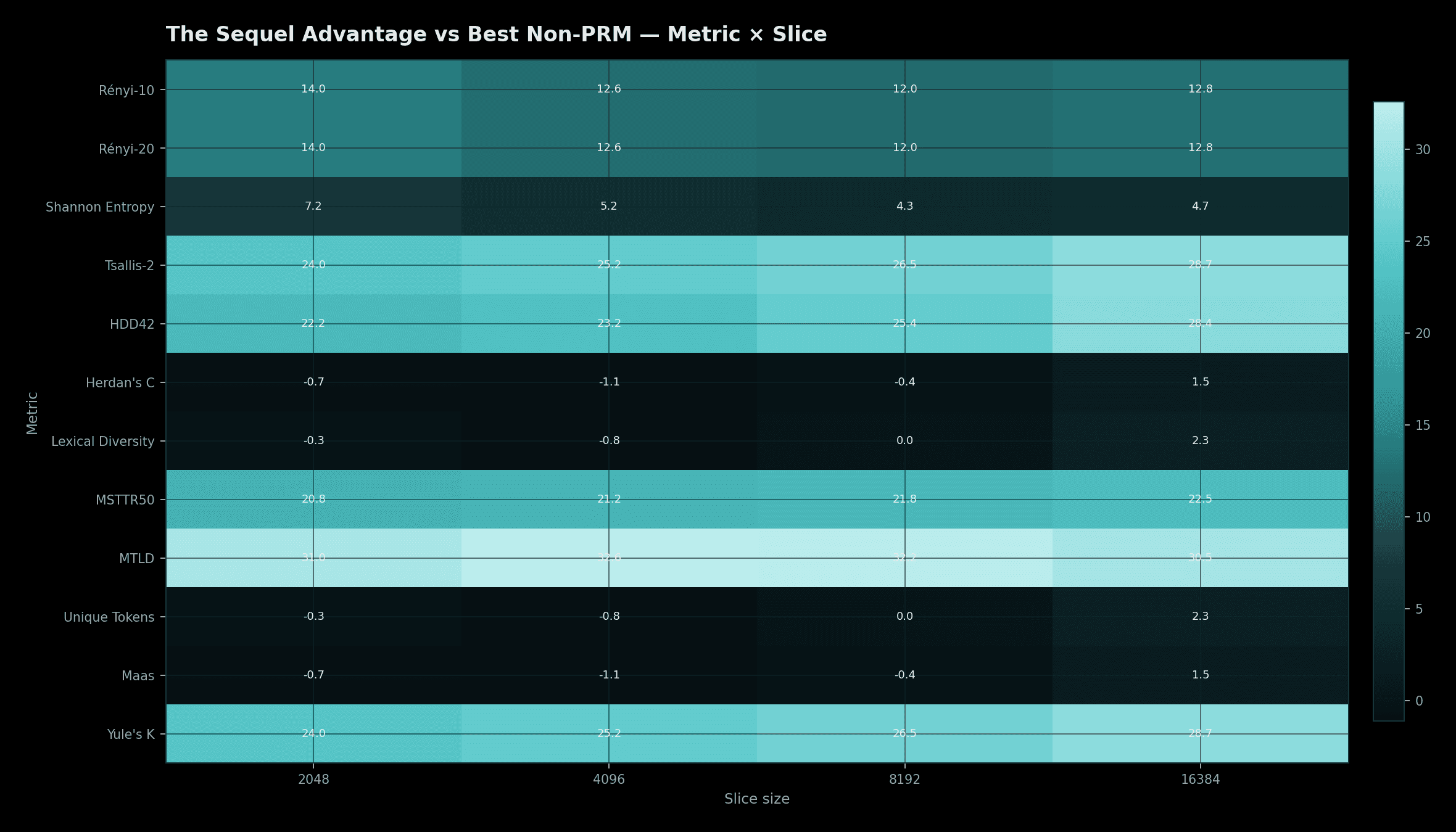
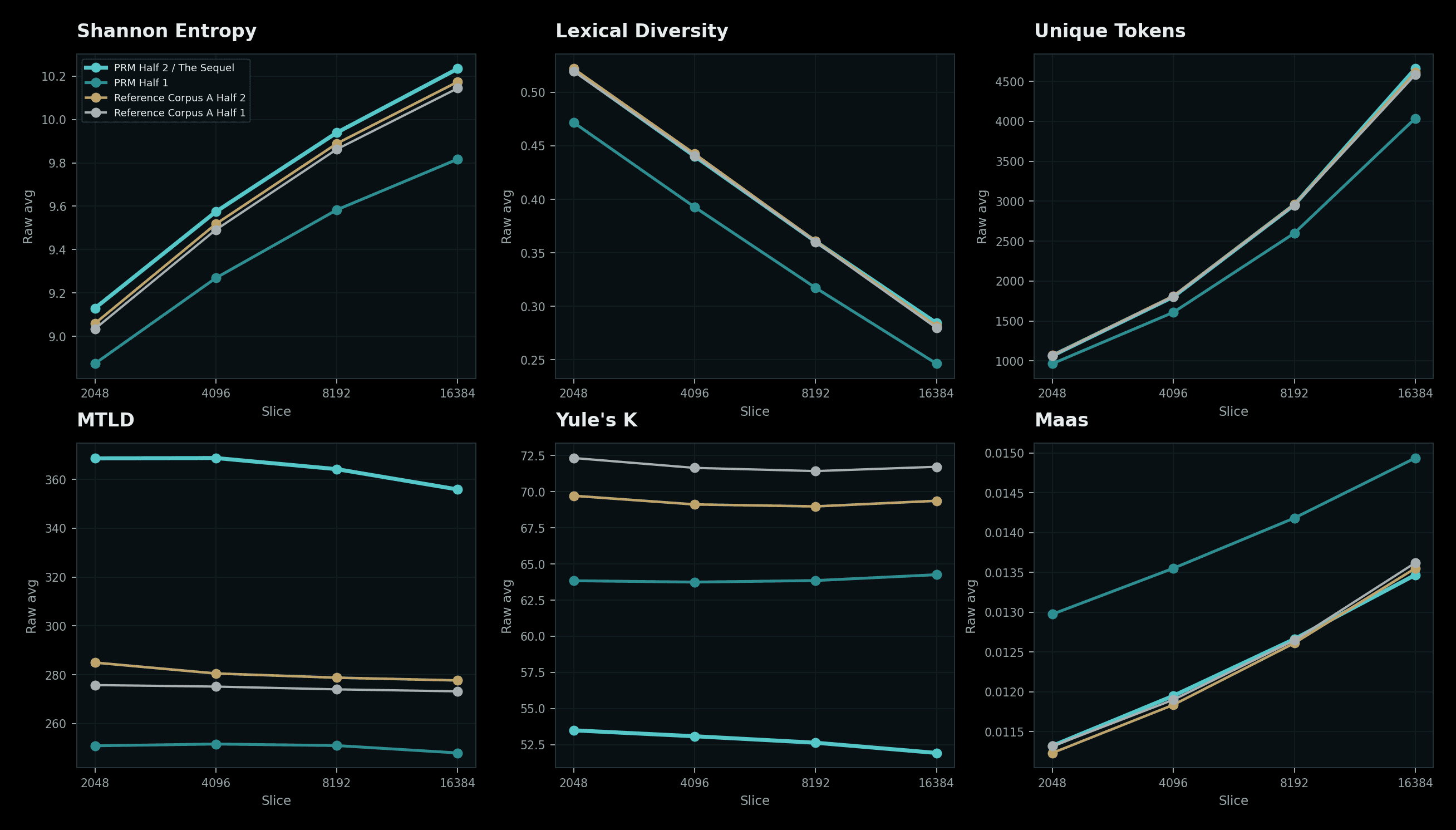
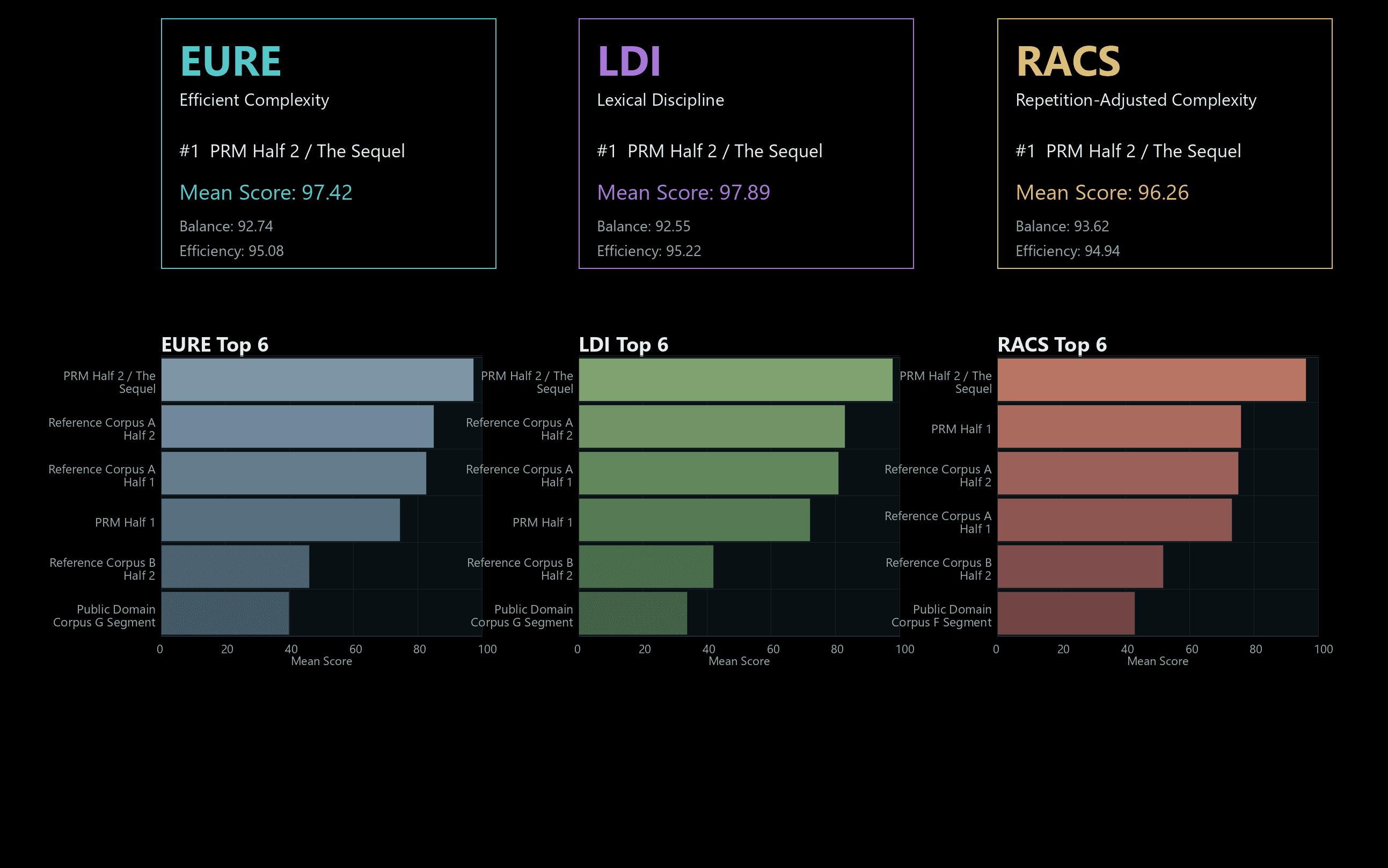
Pipeline Chart Boundary
Pipeline charts show aggregate output behavior and coverage patterns. They do not publish protected source text, private manifests, or reconstructable source maps.